


需求
将某新闻系统中某一个时间点之前的全量数据导入到新的数据库。由于系统很老旧,有很多年了,并且新闻内容是存储在数据库中的,数据量约在五十万左右。
为什么要使用Kettle:源库中存在大字段,数据量五十万左右,直接使用Navicat数据传输功能,跳板机CPU和内存直接占满卡死,导入失败,并且使用Navicat无法对一些特别的数据进行个性化处理。所以想到使用Kettle循环分页的抽取数据,每次抽取一部分就不会把跳板机搞宕机。
Kettle 下载
官方:https://sourceforge.net/projects/pentaho/files/
国内镜像(目前只到8.2版本):http://mirror.bit.edu.cn/pentaho/
实现

测试数据
原数据有隐私问题,不方便展示。这里使用新建一个测试数据。
测试表
# 源表
CREATE TABLE `t_news` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(200) DEFAULT NULL,
`content` varchar(1000) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
# 目标表
CREATE TABLE `t_news_2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(200) DEFAULT NULL,
`content` varchar(1000) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
创建MySQL函数生成测试数据·
CREATE DEFINER=`root`@`localhost` FUNCTION `rand_data`(`n` int(11)) RETURNS int(10)
READS SQL DATA
BEGIN
DECLARE str char(62) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
DECLARE str2 char(100);
DECLARE i int DEFAULT 0;
WHILE i < n DO
SET str2 = concat(substring(str, 1 + floor(rand() * 61), 50), substring(str, 1 + floor(rand() * 61), 50));
SET i = i + 1;
INSERT INTO t_news VALUES (NULL, floor(rand()*n), str2, NOW());
END WHILE;
RETURN 0;
END
# 运行函数生成一百万的数据
CALL rand_data(1000000);
Kettle转换
数据库连接省略。
涉及到的变量
- records:待转换的总条数
- page_start: 每页起始游标
- page_size: 每页数量
- page_end: 每页结束游标(MySQL用不上)
总Job
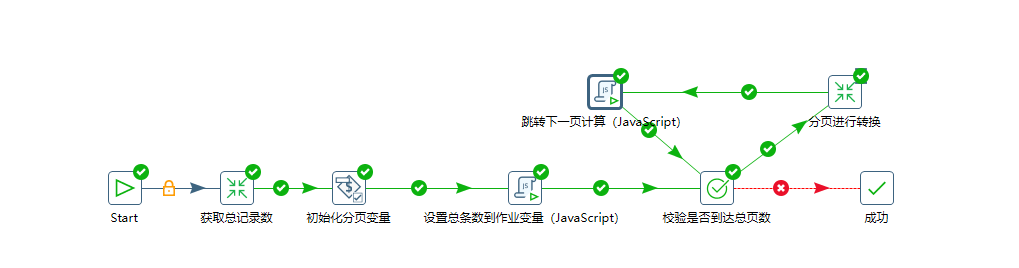
获取总条数转换
新建一个转换
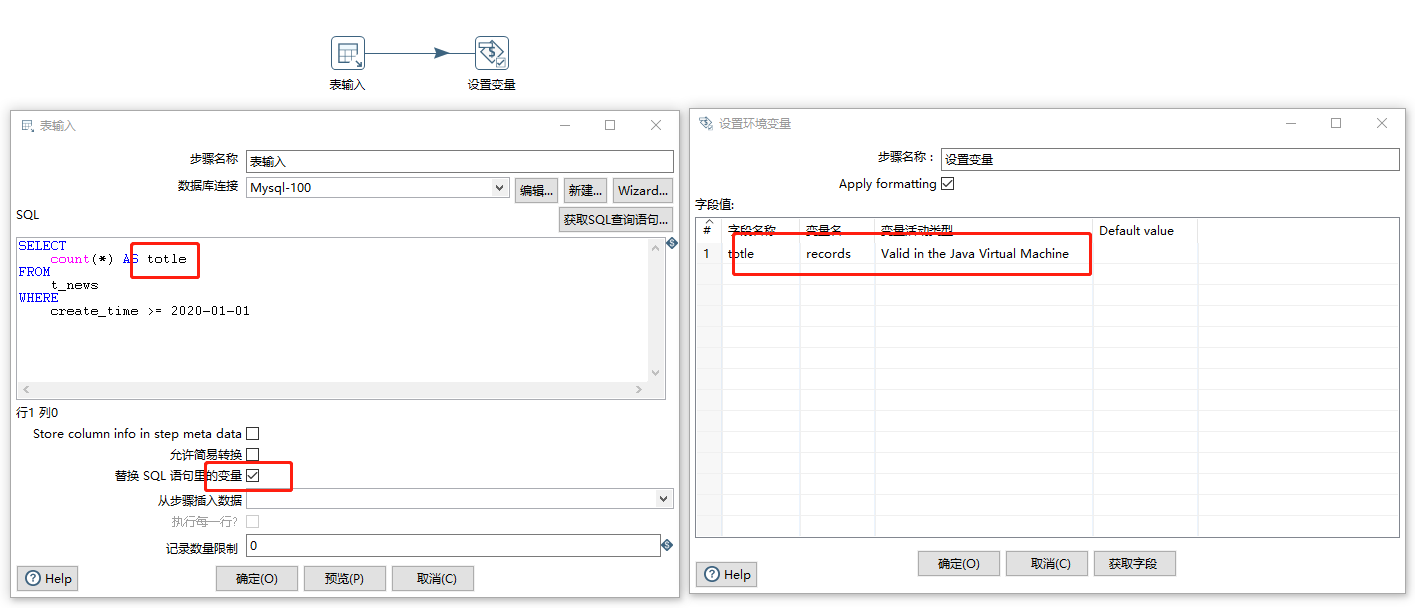
初始化分页变量
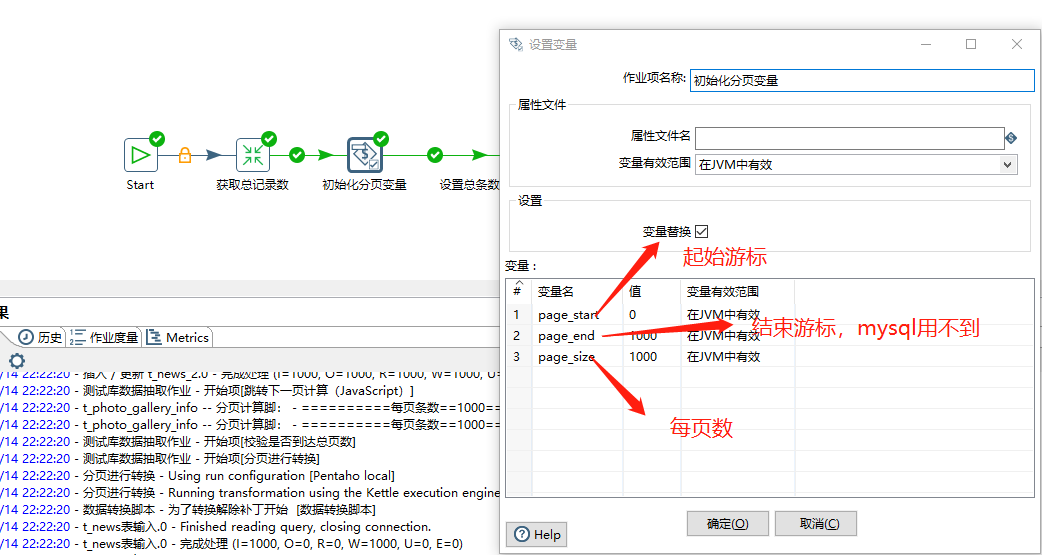
设置总条数到作业变量
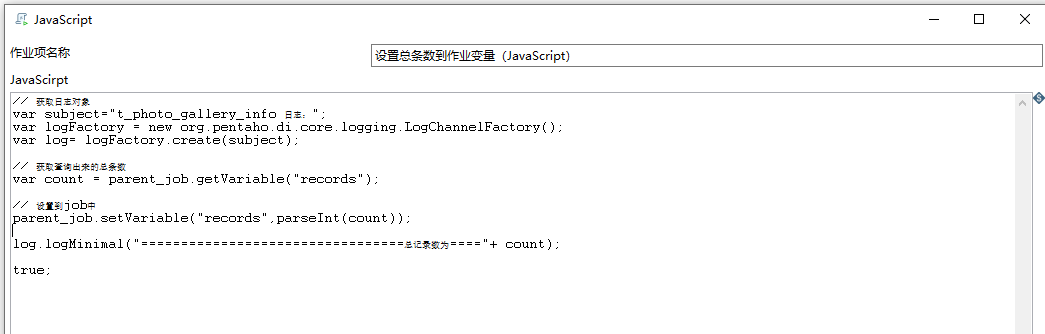
脚本
// 获取日志对象
var subject="日志:";
var logFactory = new org.pentaho.di.core.logging.LogChannelFactory();
var log= logFactory.create(subject);
// 获取查询出来的总条数
var count = parent_job.getVariable("records");
// 设置到job中
parent_job.setVariable("records",parseInt(count));
log.logMinimal("=================================总记录数为===="+ count);
true;
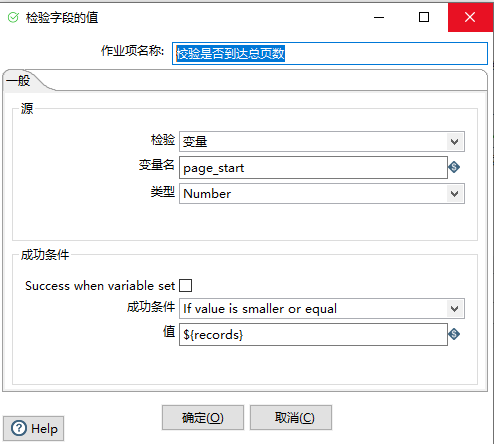
校验是否到达总页数
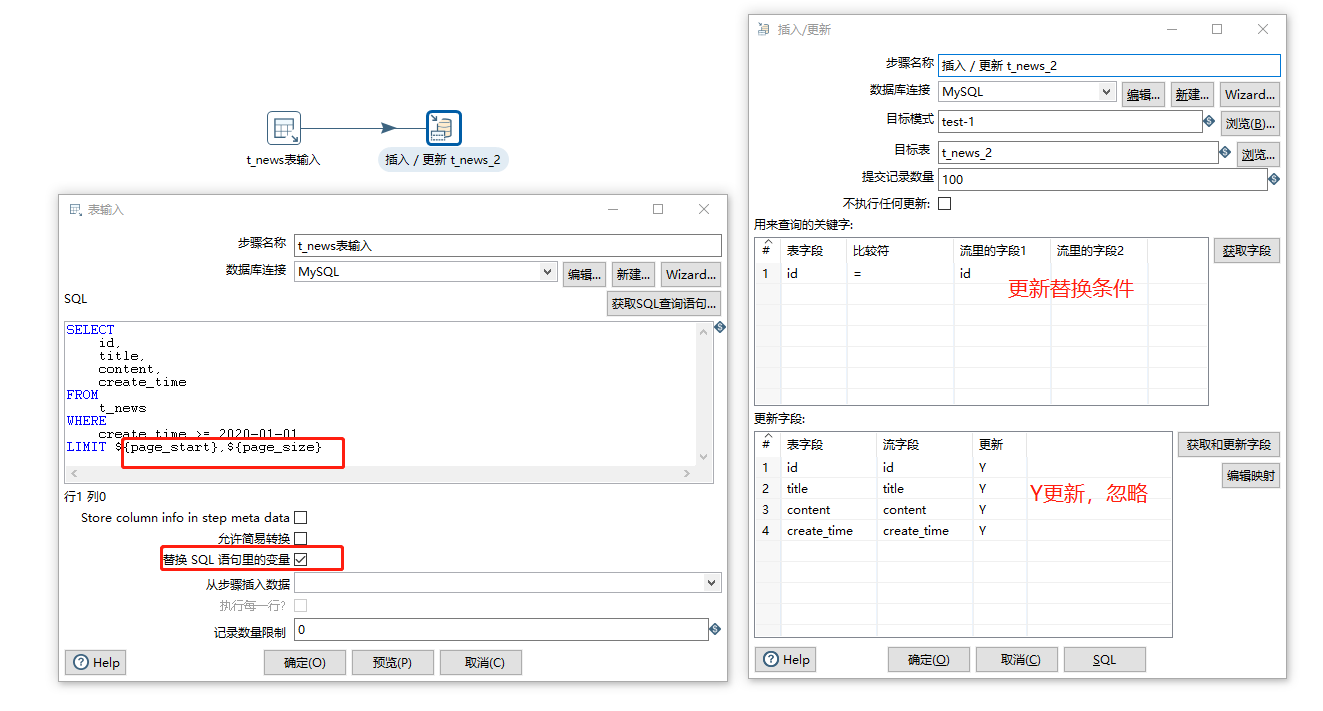
分页转换
跳转下一页
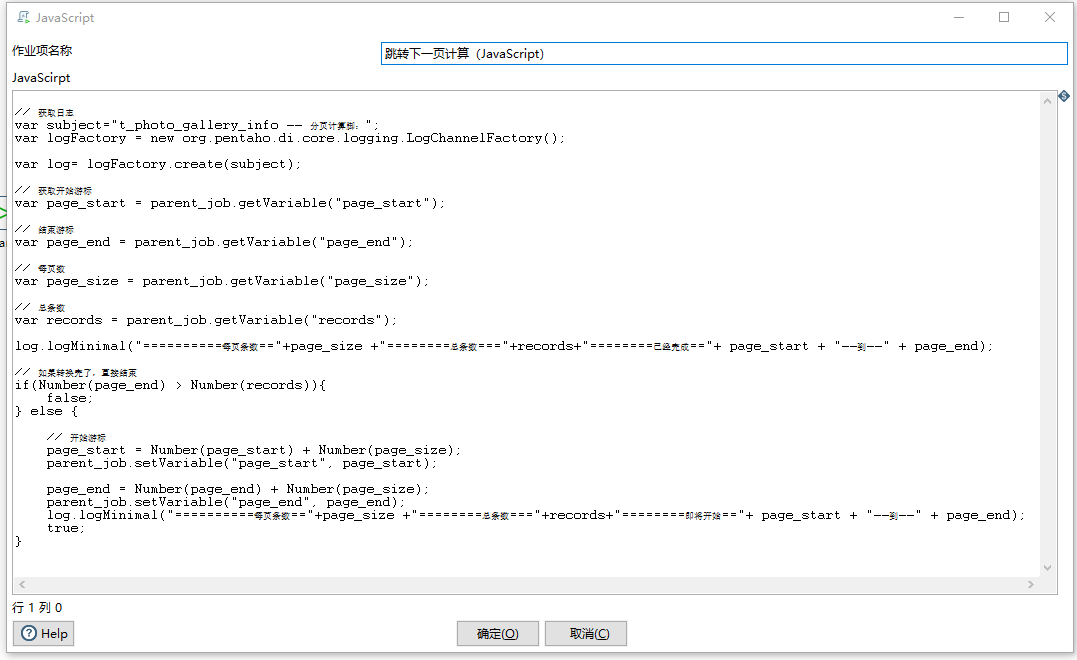
脚本
// 获取日志
var subject="跳转下一个分页";
var logFactory = new org.pentaho.di.core.logging.LogChannelFactory();
var log= logFactory.create(subject);
// 获取开始游标
var page_start = parent_job.getVariable("page_start");
// 结束游标 (MySQL可以忽略)
var page_end = parent_job.getVariable("page_end");
// 每页数
var page_size = parent_job.getVariable("page_size");
// 总条数
var records = parent_job.getVariable("records");
log.logMinimal("==========每页条数=="+page_size +"========总条数==="+records+"========已经完成=="+ page_start + "--到--" + page_end);
// 如果转换完了,直接结束
if(Number(page_start) > Number(records)){
false;
} else {
// 开始游标
page_start = Number(page_start) + Number(page_size);
parent_job.setVariable("page_start", page_start);
// 结束游标(MySQL可以忽略)
page_end = Number(page_end) + Number(page_size);
parent_job.setVariable("page_end", page_end);
log.logMinimal("==========每页条数=="+page_size +"========总条数==="+records+"========即将开始=="+ page_start + "--到--" + page_end);
true;
}
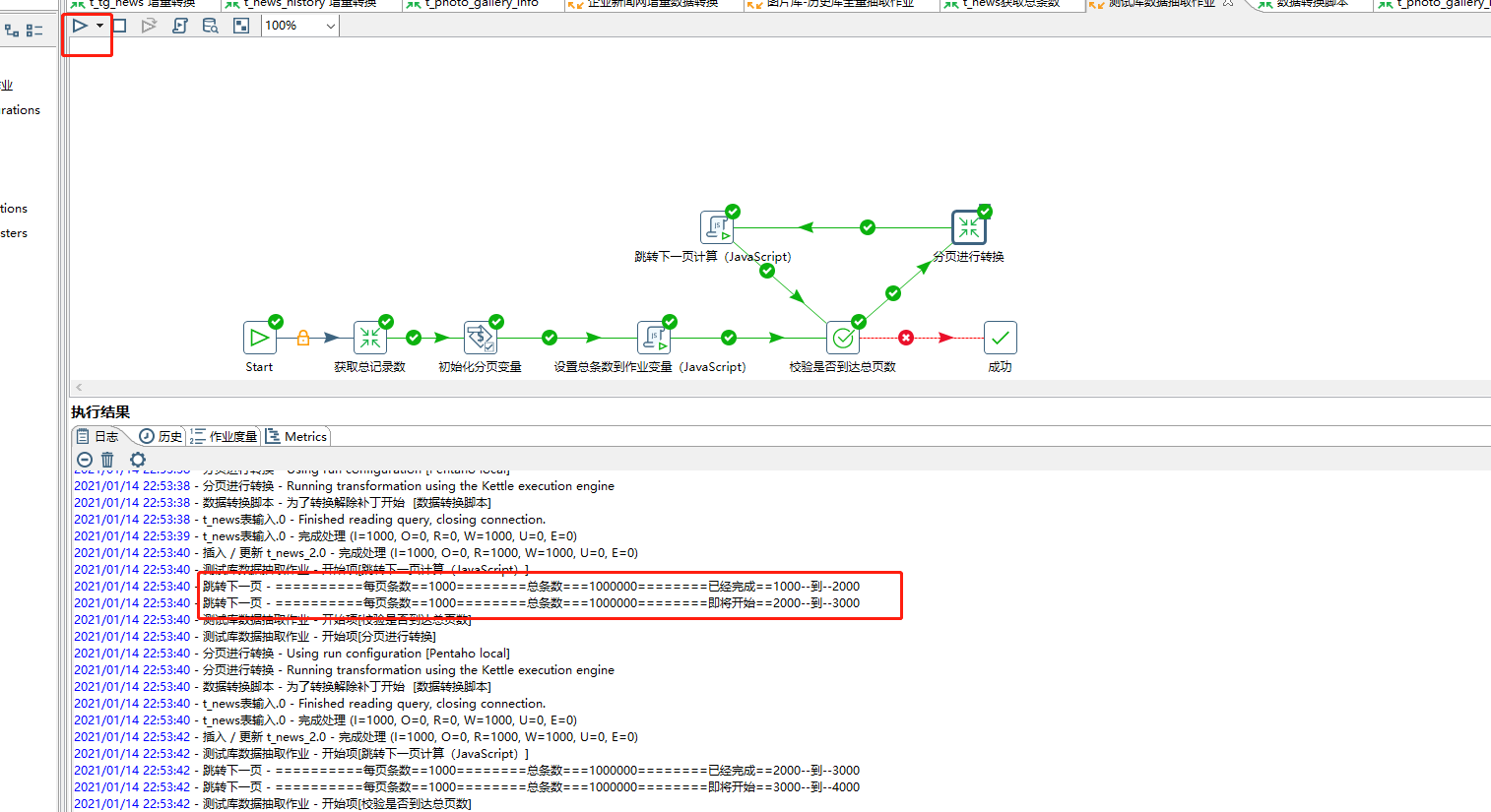
启动
启动后我们就可以看到日志信息,数据就已经开始进行转换。
扩展
以此类推,我们可以给这个Job设置定时执行,可以动态获取每天的时间,查询当天的数据进行增量的更新。
评论区